Jednou z metrik, která vás při vyhodnocování SEO aktivit zajímá, je vývoj počtu vstupních stránek z jednotlivých vyhledávačů, který reflektuje vývoj vztahu vašeho webu vůči vyhledávačům i samotným uživatelům. V následujících řádcích zjistíte, jak získávání počtu vstupních stránek, případně unikátních klíčových slov z Google Analytics, automatizovat skrze matematický software R.
Žádoucí vývoj počtu vstupních stránek může být pozitivní i negativní. Po poklesu vstupních stránek toužíte, když provedete změny ke skokovému snížení duplicitních stránek a automatizaci přesměrování – takové ty změny odstraňování technických renonsů. Nárůst počtu vstupních stránek je naopak přímým odrazem rozšiřování informační struktury – nové filtry, kategorie, nabídky (nebo vypnutí značkování PPC kampaní :)Vstupní stránky v Google Analytics

Připravte si pochutiny
- Abyste mohli R využívat, musíte si ho nainstalovat.Nainstalujte si jádro R a nějaké příjemné uživatelské rozhraní pro lepší obsluhu – doporučuji open source program RStudio, který umí pracovat lokálně i serverově. Jste-li úplní Rkoví zelenáči, zkuste si základy jazyka osvojit v bezplatném online kurzu na Code School.
- Nainstalujte si ďábelsky úžasný balíček RGoogleAnalytics od Tatvic, který přes API tahá do rozhraní data z Google Analytics. Abyste balíček zprovoznili, musíte doinstalovat pár potřebných rozšíření, jmenovitě např. jimi httr, lubridate, RCurl, bitops… Instalace krok po kroku je shrnuta zde.
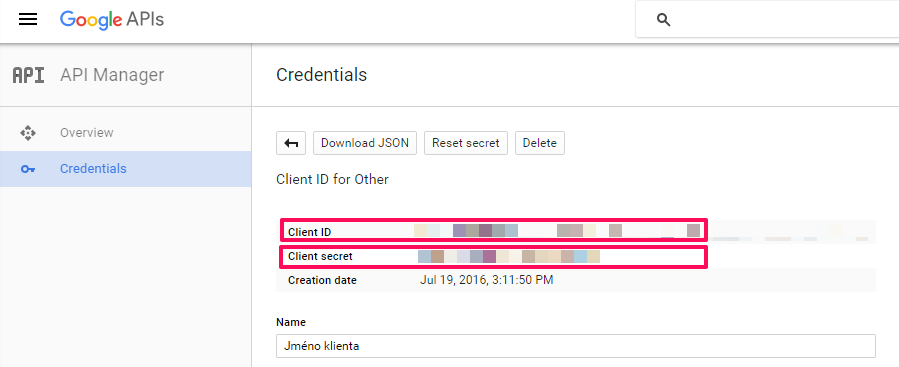
- Zařiďte přístup k vašim Google credentials. Založte si projekt v Google Developers Console. V seznamu APIs si pro tento projekt zapněte Analytics API. V Credentials si založte nový Client ID. V rámci vašeho projektu vás na kartě Credentials zajímá Client ID a Client Secret. Jedná se o jednu z autorizačních technik Google Analytics. Uživatelské jméno a heslo jsou zastaralé způsoby ověření a neměly by se používat. Pokud tápete, zkuste tento návod.
Samotné dolování dat
Postupně budete spouštět v konzoli různé scripty, na jejichž konci vás čeká tabulka dat vytáhnutá z Google Analytics. Popis příkazů je rozepsán na blogu Tatvic, detailnější vhled případně zde.
Autorizujte přístupy aplikace. V první vlně ověříte
přístup aplikace k vašemu účtu Google Analytics. Jen si pamatujte, že
access token vyprší po 60 minutách, kdy si ho budete muset obnovit
příkazem ValidateToken(token).
require(RGoogleAnalytics)
client.id <- "xxxxxxxxxxxxxxxxx.apps.googleusercontent.com"
client.secret <- "xxxxxxxxxxxxxxxxxxxxxxxx"
token <- Auth(client.id,client.secret)
save(token,file="./token_file")

- Získávejte data o vstupních stránkách z vyhledávačů. V další vlně si napíšete dotaz pro API Google Analytics.
query.list <- Init(start.date = "YYYY-MM-DD",
end.date = "YYYY-MM-DD",
dimensions = "ga:date,ga:landingPagePath",
metrics = "ga:entrances,ga:pageviews",
max.results = 10000,
sort = "-ga:date",
filters = "ga:medium==organic;ga:keyword!@název domény",
table.id = "ga:xxxxxxx")
ga.query <- QueryBuilder(query.list)
ga.data <- GetReportData(ga.query, token, paginate_query = TRUE)
Stěžejní je pro vás příkaz Init(),
přes který formulujete parametry dotazu na Google Analytics. Přes GetReportData()
můžete povolit měření v případě překročení povolených Core
Reporting API limitů. V příkladu výše chceme pro konkrétní den
vytáhnout seznam všech vstupních stránek pouze pro návštěvy
z vyhledávačů. Analýzu omezíme jen na generické fráze. Jsou vyloučeny
návštěvy z brandových dotazů, které výrazně vychylují aktivní
brandové PPC. Tento seznam si v tomto případě obohacuji o pageviews
metriky jako je počet vstupů, zobrazení stránek.
Metrik si můžete vyžádat více. Stačí se inspirovat v kompletní databázi platných kombinací metrik a dimenzí. Pokud občas používáte rozšíření Google Analytics pro Google Spreadsheets, sémantiku dotazů máte v malíku. Nebojte. R je hodné a za každý krok vedle vám řekne, co přesně jste udělali špatně.
Pokud se cítíte ztraceni, vždy můžete sáhnout po nápovědě –
help(Init), help(GetReportData).
- Převeďte datum na správný formát

ga.data$date <- as.Date(ga.data$date, "%Y%m%d")

- Získejte počet vstupních stránek
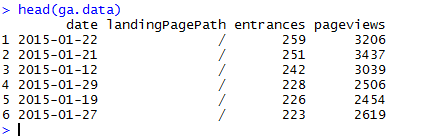
Počet unikátních vstupních stránek z vyhledávačů po jednotlivých
dnech (dimenze ga:date) získáte za pomoci agregace dat – kombinace vzorce
aggregate() a proměnné length, která vrací počet
složek seznamu (případně sum pro součet). Ze všech získaných hodnot si
udělejte tabulku, zde nazvanou landing.pages. Výsledný dataset je o dvou
sloupcích, kdy v prvním sloupci je časová osa (v našem případě po
dnech) a v druhém sloupci hodnoty o počtu vstupních stránek.
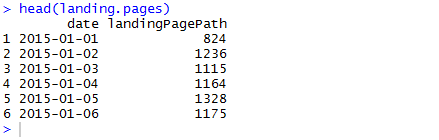
Sloupce si můžete přejmenovat tak, aby vašemu jazyku seděly více.
names(landing.pages) <- c("Reporting Period","Count of Landing Pages")
Tabulku si můžete vyexportovat do .csv přes příkaz write.table().Stáhněte
si podrobnější markdown včetně
scriptů, které budete moci po otevření v RStudiu rovnou spouštět bez
složitého kopírování. Stačí najet na příslušný řádek a spustit
příkaz klávesovou zkratkou Ctrl+R.
- Zjistěte trend počtu vstupních stránek
plot(landing.pages,
type=„l“).
Dokonce můžete načrtnout i předpokládaný vývoj za pomoci funkce
HoltWinters().
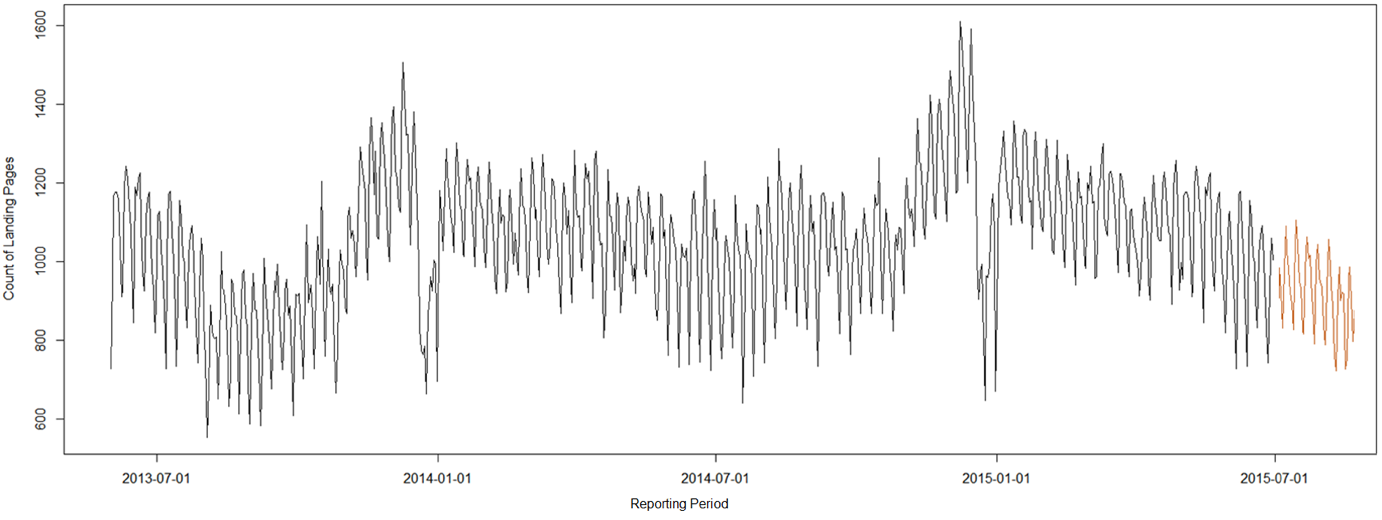
- Data zasaďte do kontextu

Nikdy se nepouštějte do vyhodnocování počtu vstupních stránek bez znalosti trendu návštěvnosti. Počet návštěv na jednu vstupní stránku roste s lepšími pozicemi a vyšší hledaností tématu. Rostoucí počet vstupních stránek s klesajícím podílem není na první pohled žádná hitparáda. Opravdu ne? Na určité stránky vám uživatelé chodí přes pestrou škálu dotazů. Rozhodnete se tedy jejich obsah rozdělit do více stránek. Rozšiřujete informační strukturu, ale zároveň očekáváte, že podíl vstupů na tyto stránky bude nižší, resp. se rozloží mezi více stránek. Jindy jste provedli strojové odstraňování duplicitních stránek a očekáváte pokles vstupních stránek za rostoucího vývoje průměrné návštěvnosti na stránku.

query.list <- Init(start.date = "YYYY-MM-DD",
end.date = "YYYY-MM-DD",
dimensions = "ga:date,ga:keyword",
metrics = "ga:entrances",
max.results = 10000,
sort = "-ga:date",
filters = "ga:medium==organic;ga:source=@seznam;ga:keyword!@název domény",
table.id = "ga:xxxxxxx")
U zásadnějších strukturálních změn, kdy se snažíte lépe zaměřit
obsah, pravděpodobně rozšíříte strukturu webu. S kvalitnějším
pokrytím longtailu se zvýší počet unikátních dotazů, ale počet dotazů
na stránku se sníží – odraz jasnějšího cílení.
query.list <- Init(start.date = "YYYY-MM-DD",
end.date = "YYYY-MM-DD",
dimensions = "ga:date,ga:source,ga:landingPagePath",
metrics = "ga:entrances",
max.results = 10000,
sort = "-ga:date",
filters = "ga:medium==organic;ga:keyword!@název domény",
table.id = "ga:xxxxxxx")
Do příkazu aggregate() přidáte podmínku, že chcete shlukovat
podle datumu i zdroje:
landing.pages.s <- aggregate(landingPagePath ~ date+source, ga.data, length)
Ve funkci pro spojnicový graf nesmíte zapomenout na podmínku vykreslení
linky vždy pro příslušný zdroj:
plot(landing.pages.s$date[landing.pages.s$source=="seznam"], landing.pages.s$landingPagePath[landing.pages.s$source=="seznam"], type="l")
Na grafu výše vidíte, že Google zareagoval na významnou změnu webu (jako
je přechod na novou doménu) mnohem dynamičtěji než Seznam. Toto zjištění
šlo ruku v ruce se stavem indexu.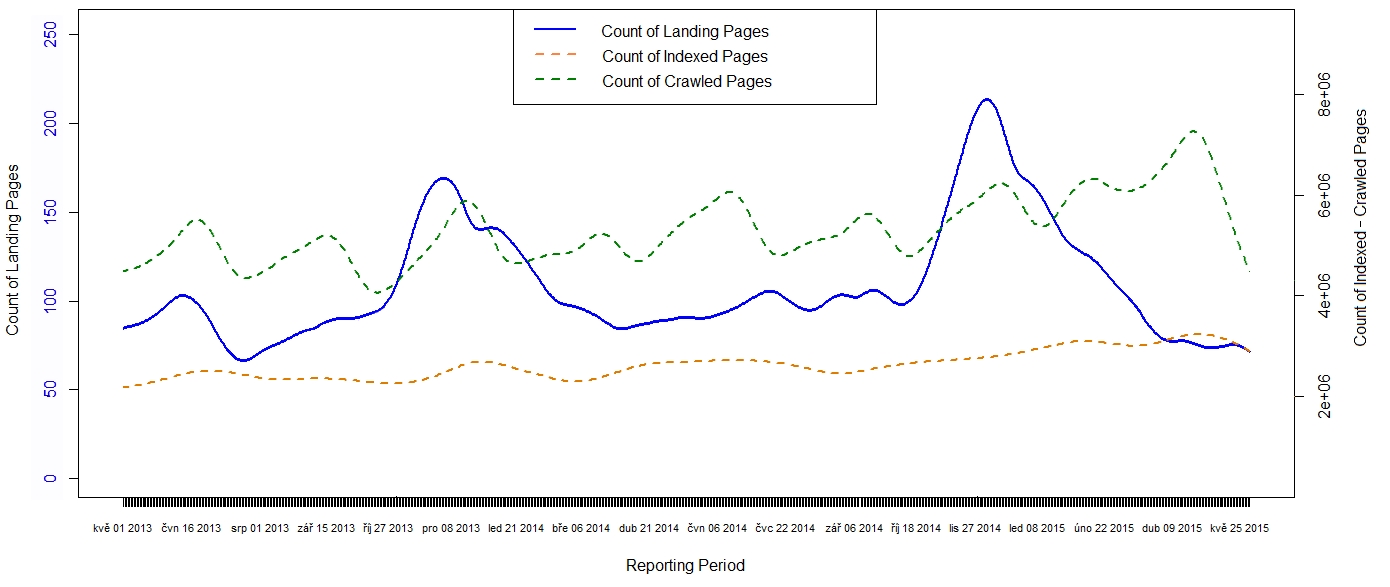
Vstupní stránky představují obraz zájmu uživatelů o naše webové stránky. Aby se o nás ale mohli zajímat, musí nás vidět. Proto byste měli mít přehled i o zájmu vyhledávačů o vaše stránky. Sledujte jak vývoj počtu vstupních stránek z vyhledávačů, tak i počet zaindexovaných či dokonce crawlovaných stránek. Na měření botů jsou různé postupy, například odchytávat si access logy, nebo třeba přes Universal Analytics – jen buďte obezřetní, abyste si spíše neuškodili. Třeba zpomalením načítání stránek jako v druhém uváděném případě. Nízká míra zaindexovanosti značí možné problémy při průchodu robota, nebo při zařazování do indexu. Nízký poměr zaindexovaných stránek vůči crawlovaným může znamenat hodně stránek v Supplemental Indexu. Vyšší tendence robota crawlovat web je i přirozený důsledek častých změn obsahu webu nebo větších strukturálních změn.
Monitorování počtu vstupních stránek by se mělo stát milou rutinou. Můžete ho sledovat přímo v Google Analytics, nebo opět využít trochu té svěží automatizace. Například přes R, který nabízí řadu možností, jak z dat vytěžit maximum. V článku není prostor na podchycení jeho komplexnosti, ale každý si v něm najde své.
Důležité je se nikdy nesmířit s absolutním číslem vybrané metriky, ale nahlížet na ni z různých stran. Vývoj počtu unikátních vstupních stránek odráží předpokládaný vývoj vámi implementovaných změn, ale taky dává varovné signály nečekaného. My jsme například nedávno kontrolovali, jak rychle vyhledávače reagují na přechod webu na novou doménu. Dává smysl na trend nahlížet ve vztahu atraktivity pro uživatele (CTR, návštěvnost) či zájmu robotů o stránky (pozice, indexace vs. crawlování). Je také důležité sledovat, jak měnící se struktura vstupů ovlivňuje další metriky, jako jsou transakce, či rozvržení dotazů, přes které uživatel jednotlivé stránky nachází.
Stáhněte si obsáhlejší markdown včetně scriptů, které po otevření v RStudiu budete moci rovnou spouštět klávesovou zkratkou Ctrl+R. Najdete v něm podrobněji rozepsané příkazy včetně návodu na tvorbu hladkého grafu s více liniemi a vedlejší osou.
Dočetli jste až sem a stále nemáte dost? Přijďte se nachytřit 16. 6. na SEO restart 2017.
Díky za zajímavé postřehy k článku Pavlu Jaškovi.
Na další se budu těšit od vás. Jak a kdy byste informace o vstupních stránkách využili vy?
Koukám, že stránka http://techpad.co.uk/content.php?… už neexistuje. Tip na návod někde jinde?
Další zajímavý studijní materiál… díky!
@Miroslav Pecka. Děkuji za informaci o neaktuálnosti odkazu. Internet Archive to naštěstí jistí. S instalací balíčku pomáhá i samotný program, který vám v konzoli vždy napoví, co je třeba k zdárné instalaci ještě donastavit, dostáhnout…
Pingback: Google Analytics SEO report | Miroslav Pecka
<!--texy-->Díky za tip.